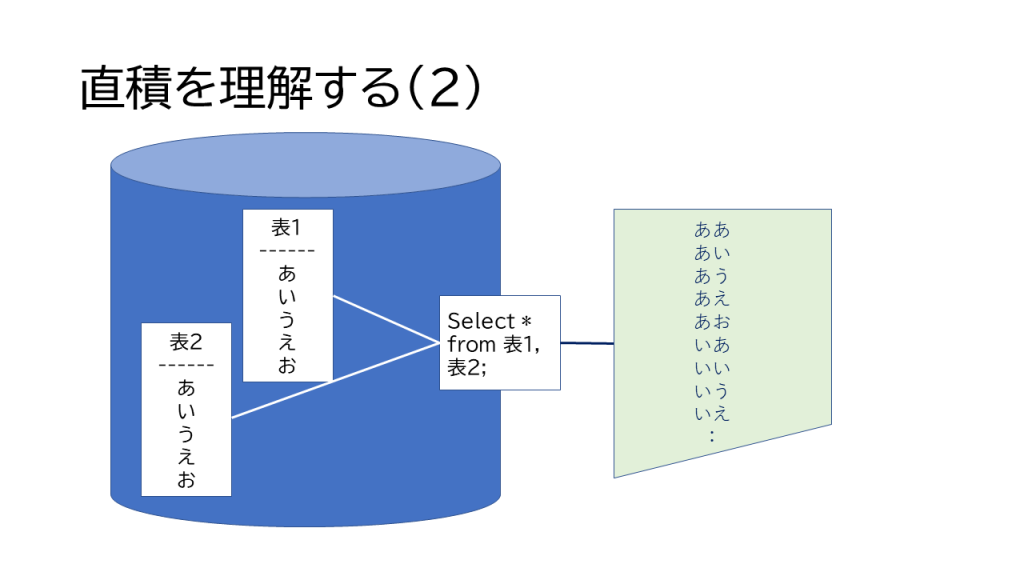
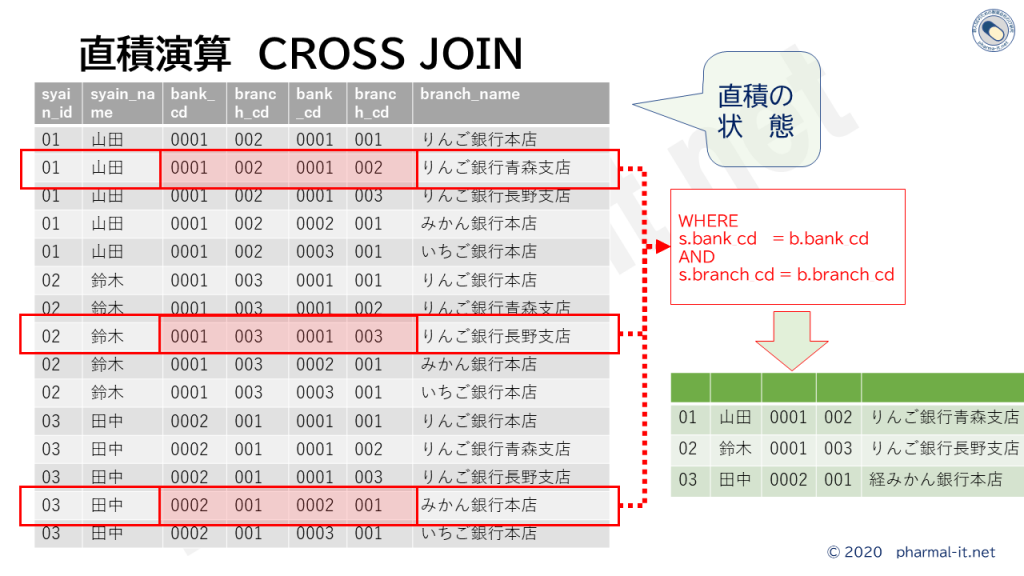
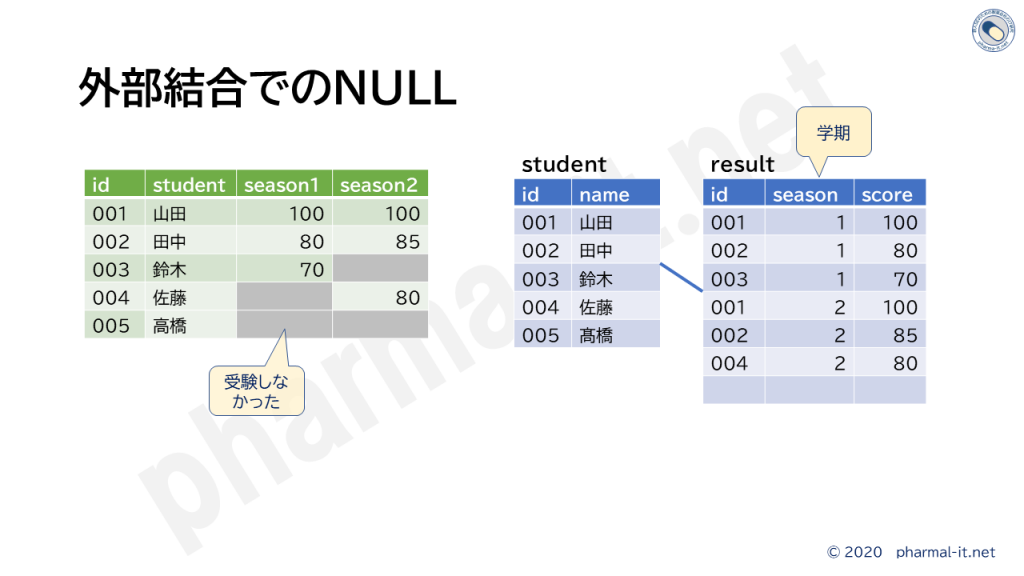
製薬ITとは関係ないのですが、おまけです。 躓きやすいところと、勘違いしやすいところなど 新人SEのためのSQL 外部結合 Outer Join で注意すべき3つの 簡単に直積演算を体感するスクリプト おまけです。テーブルとか作らずに、簡単に 直積演算でSQLを理解する(2) 明けましておめでとうございます。滅多に更 直積演算でSQLを理解する select文を投げたら帰ってこない。i 新人SEのためのSQL 外部結合とNUL... NULLがややこしいという記事を書きまし 新人SEのためのSQL NULL SQLでややこしくて、よく理解しないまま FacebookXBlueskyHatenaCopy