実消化システムの概要
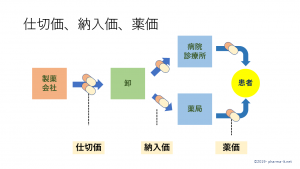
医療用医薬品は、製薬会社から医薬品卸に納入され、医薬品卸から、病院、診療所、薬局といった医療機関に納入されたのち、医療機関において、患者に対して投薬、処方されます。
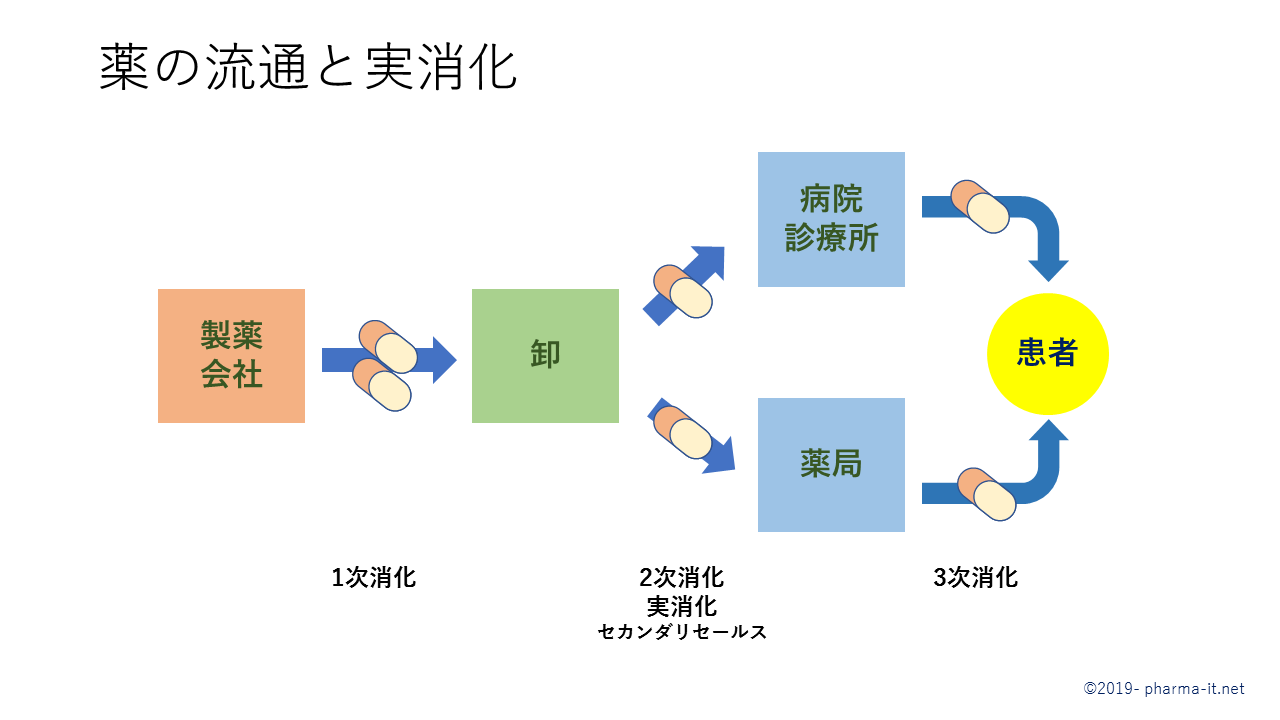
製薬会社から医薬品卸への納入を『一次消化』、医薬品卸から、医療機関への納入を『二次消化』、あるいは、『実消化』、『セカンダリセールス』と表現します。
医療機関は、通常の言い方をすれば、『小売り』であるといえます。
卸→小売→消費者の経路で物を売るメーカーならどこも、どの小売に売れたのかをマーケティングや、営業担当者の評価の観点から把握する必要がありますが、製薬会社は、それ以上に、医師や薬剤師に薬の安全性や適正使用についての情報を伝達する必要があり、なによりもそのために、どこの小売に納入されたかを知る必要があります。
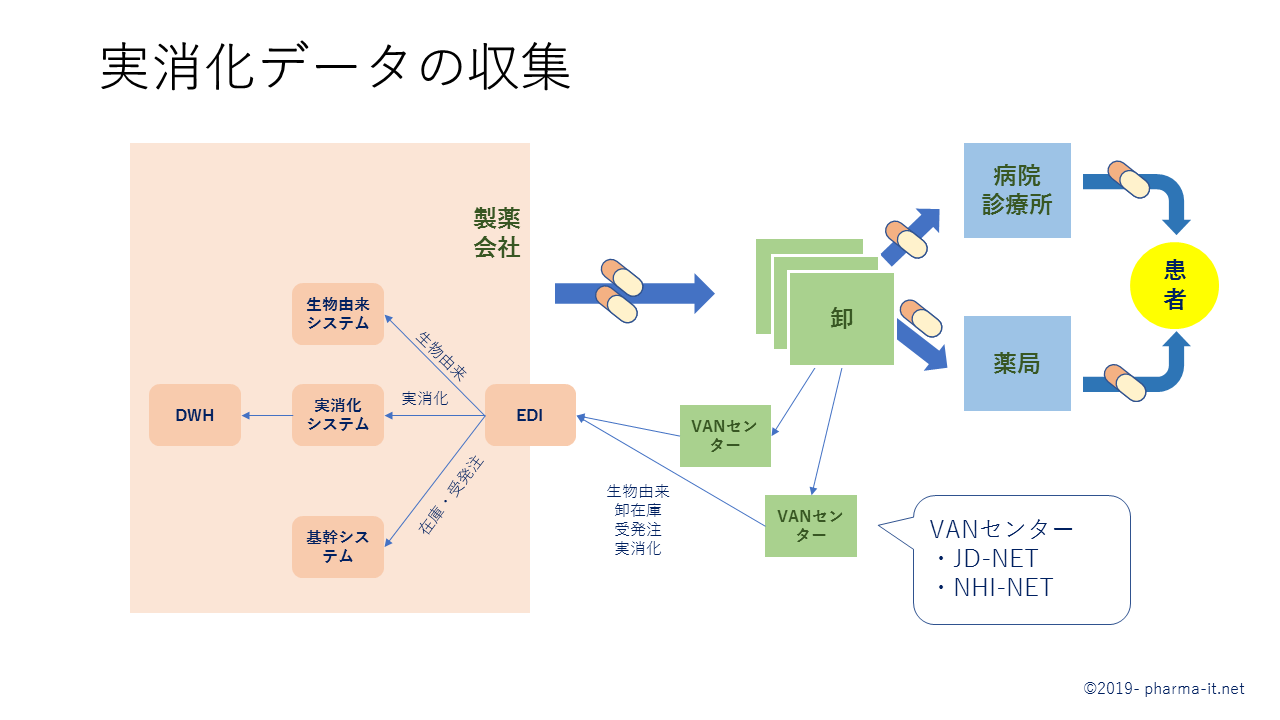
そのため、どの製薬会社も、自社でシステムを保有しているかどうかは別にして、実消化データを収集、蓄積、管理しています。
卸から医療機関への販売伝票をVANを通じて受け取り、データのクレンジングを行なった上で蓄積します。また、卸側のコード変更にあわせて、メーカー側の蓄積データを洗い替えることもよく行われています。
この蓄積データはデータウェアハウスに連携され、マスターや販売目標など他のデータと組み合わされて、さまざまなレポートとして本社、営業第一線、流通部門に提供されます。
製薬会社は、医薬品卸とVANを通して繋がっており、受発注、在庫、実消化、生物由来品納入などのデータのやり取りをしています。
その代表的なものが、JD-NETとNHI-NETです。
実消化の場合、卸の営業所、納入先医療機関、製品などのコードと名称、数量、金額などの情報が入手できます。
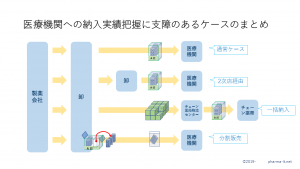
ここでひとつ問題となるのは、納入先医療機関のコードが、各卸でバラバラだということです。
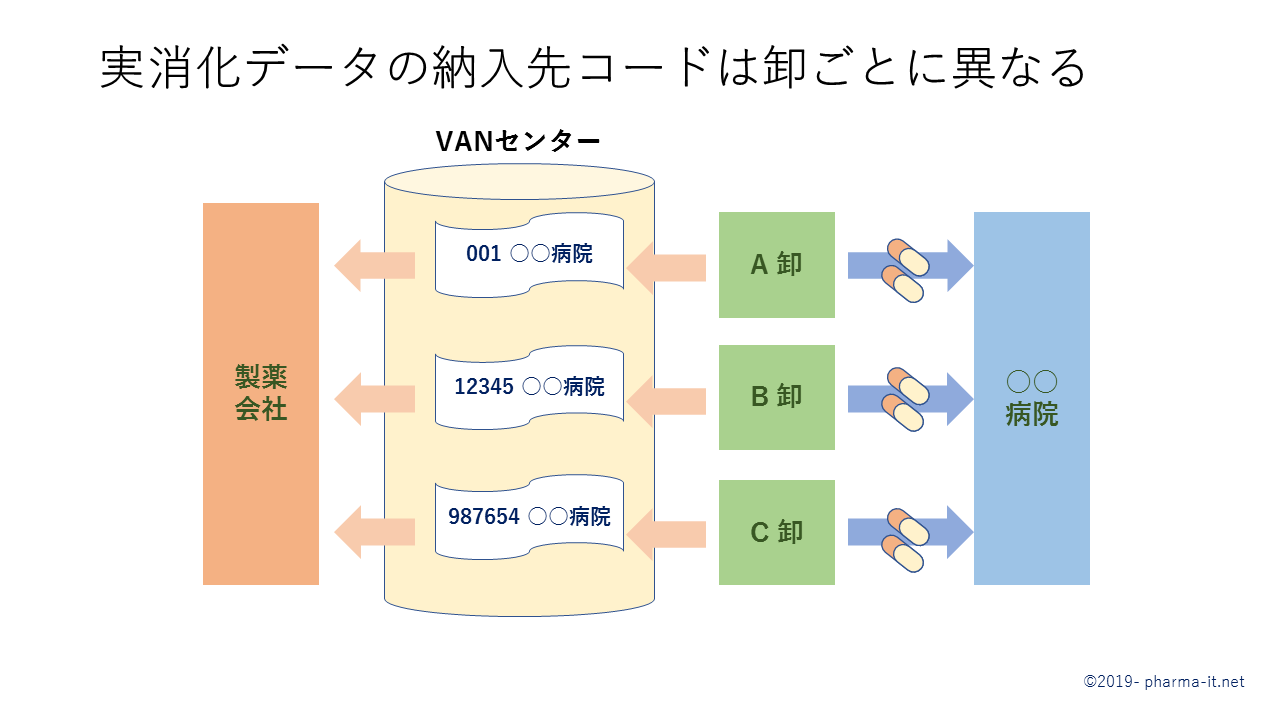
製品のコードは、ひとつの製品について「統一商品コード」が使用されて、どの卸も同じコードでやり取りをします。しかし、医療機関のコードは各社がバラバラのコード体系で、たとえば『東京女子医大付属病院』に対して、卸ごとに異なるコードが付与されています。
したがって、製薬会社は自社の医療機関のコードと、卸のコードを紐付ける必要があり、この紐付けのマスタを整備し続ける必要があります。
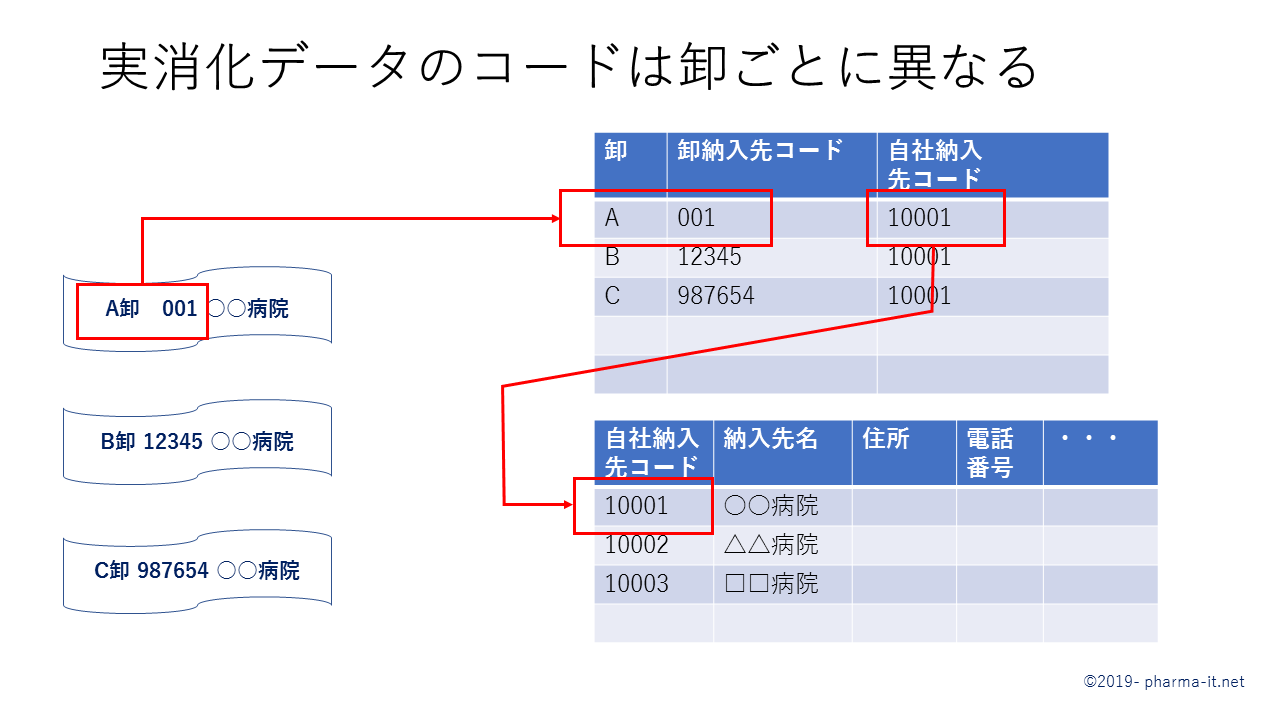
この紐付けが行われないと、製薬会社は、自社製品が、どの医療機関に納入されたのかを把握することが出来ません。たとえば、新たな病院が開業する際も、卸は新たな番号を採番します。その医療機関に対する紐付けデータはまだ存在しませんから、卸から届く実消化データは、どこかわからない医療機関に納入されたという状態になります。
実消化データ内には、納入先の名称や住所の情報も含まれていいます。製薬会社のマスターを整備する担当者は、納入先施設不明リストの中から、納入先名や住所などの情報を頼りに、自社のマスタと卸のマスタの紐付け情報を登録することになります。

いわゆる実消化システムというのは、
『VAN経由で卸から入手したデータのクレンジングをして、自社コードを取り付けて蓄積し、BIシステムへ引き渡すシステム。』
ということになります。
商品は統一と先に述べましたが、卸毎の納入先と自社施設との紐付け以外にも、たとえば、販売なのか、返品なのか、値引きなのかという取引区分も卸ごとに異なりますし、その他、そもそもデータのレイアウトも微妙に異なります。
・卸毎のデータフォーマット情報
卸ごとに、データの何桁目から何桁を切り出すかという情報
・卸毎の取引区分の情報
卸ごとに、販売、返品、値引きといった取引区分を示すコードが異なるため、このコードを自社の定義に合わせる必要がある。
※例えばJD-NETであれば、大まかには定義されているが、複数のVANからデータを入手するため、変換機能は必要となる。
・卸毎の組織と自社定義の卸組織のマッピング
製薬会社側は、卸の組織別の納入実績を把握するため、自社コードで卸組織をマスタ化しています。そのため、卸の定義する組織と自社定義の組織のマッピングが必要となります。
そのほかにも、日付が正しいか、商品コードが正しいかなどのチェックが行われ、それをクリアしたデータが、BIシステムに連携されます。
2019.7.7 修正 2021.2.4